Administrators Guide¶
The administration section of this documentation covers topics related to installing the software module in an existing database. We assume general knowledge about PostgreSQL. No particular Unix or programming experience is required.
MGRID HDL is a set of PostgreSQL extension modules that implement the Healthcare Datatypes as a set of user defined types (UDT) and user defined functions (UDF).
MGRID HDM is a collection of Healthcare Data Models that implement the normative HL7v3 Reference Information Models and their associated vocabulary.
Installing the software¶
Before the module can be used in a database, the package files must be installed on the host operating system on which the database server software is running. The installers provided by MGRID can run in attended (with user interface), as well as unattended modes. The default mode of the installer is to run in attended mode.
The installer only writes files to the PostgreSQL
servers share directories. It does
NOT update databases, or in any other way change databases or control the
running server. The installer can be executed regardless of whether the
PostgreSQL server is running or not. The installer can be executed as many
times as desired.
Every successful installation creates a logfile called
/tmp/install-mgridhdl.log. This file
contains a log of all files copied by the installer. When the installer
exists due to an error, the
newest /tmp/bitrock_installer*.log
contains the logfile of the aborted installation.
Installing with user interface (attended)¶
The installer can run in an attended mode on both text-only terminals, as well as terminals in an X-Windows environment. First download the installer from the MGRID website. Make sure the installer has executable bits. Then run the installer.
$ ls -la
total 4488
drwxrwxr-x. 7 mgrid mgrid 4096 Aug 16 13:52 .
drwxr-xr-x. 8 mgrid mgrid 4096 Jul 7 06:50 ..
-rwxrwxr-x. 1 mgrid mgrid 4565656 Aug 16 13:56 mgridhdl-2.0-linux-x64-installer.run
$ chmod +x mgridhdl-2.0-linux-x64-installer.run
$ ./mgridhdl-2.0-linux-x64-installer.run
After a few seconds, on X-window terminals, the welcome screen will appear. Press Forward to continue with the installation, or Cancel to stop the installer. The next screen will be a license accept screen.
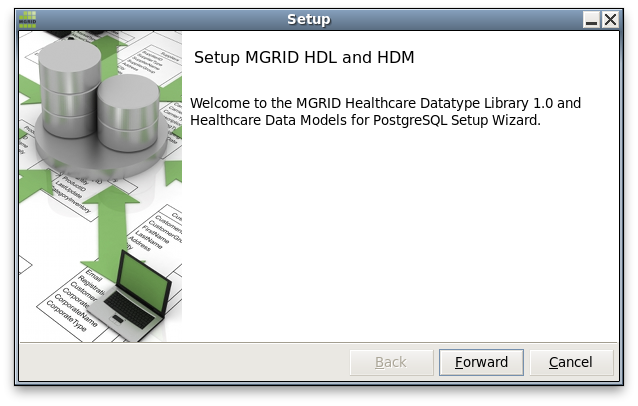
After accepting the license, the user can select the Healthcare Data Models (HDM) to download and install. Note that if data models are select, a connection to the internet is needed to download the models. For database servers that have no access to the internet, first run the installer on a database server that does have an internet connection and select the required data models. Then manually copy the corresponding files from the servers share extension directory to the servers that do not have a connection to the internet.
In this example we select SNOMED-CT, and then click Forward.
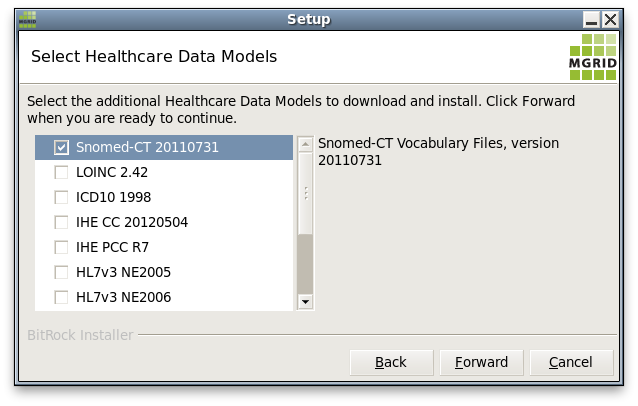
The next step is to select the PostgreSQL server to install the HDL and HDM extensions in, by selecting that installations pg_config executable.
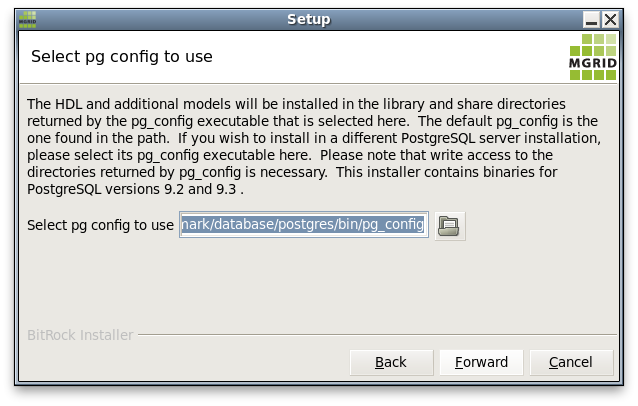
Next the installer checks if the selected PostgreSQL server matches the HDL and HDM version. If all is well, the following screen is shown. This is the last screen before the actual downloads and installation starts.
The next screen shows progress of downloads and installation of files.
When no errors occur, the following screen is down. If there are
errors, please consult the
file /tmp/install-mgridhdl.log for
details.
After succesful installation of the software, it is possible to use the extensions (modules) in databases, as is described in section Installing on PostgreSQL
Installing without user interface¶
Besides running with a user interface, the MGRID HDL and HDM installer can also run in unattended mode. This is mainly useful for automated installations. All the parameters for the installer must be supplied on the command line, or in an options file.
To view available command-line options, run the installer with –help
$ ./mgridhdl-1.0-linux-x64-installer.run --help
MGRID HDL 1.0
Usage:
--help Display the list of valid options
--version Display product information
--optionfile <optionfile> Installation option file
Default:
--unattendedmodeui <unattendedmodeui> Unattended Mode UI
Default: none
Allowed: none minimal minimalWithDialogs
--debuglevel <debuglevel> Debug information level of verbosity
Default: 2
Allowed: 0 1 2 3 4
--mode <mode> Installation mode
Default: gtk
Allowed: gtk xwindow text unattended
--debugtrace <debugtrace> Debug filename
Default:
--enable-components <enable-components> Comma-separated list of components
Default:
Allowed: snomedctvocab_20110731 loinc_242 icd10_1998 ...
--disable-components <disable-components> Comma-separated list of components
Default: snomedctvocab_20110731,loinc_242,icd10_1998 ...
Allowed: snomedctvocab_20110731 loinc_242 icd10_1998 ...
--installer-language <installer-language> Language selection
Default: en
Allowed: en
--pg_config_path <pg_config_path> Select pg config to use
Default:
The following example shows how to invoke the installer to install the
extensions in the server
installation /usr/local/postgresql-9.2
and with the HL7v3 models of NE2011, Snomed-CT of 2011 and Loinc.
Install MGRID HDL unattended¶
./mgridhdl-1.0-linux-x64-installer.run \
--pg_config_path /usr/local/postgresql-9.2/bin/pg_config \
--mode unattended \
--enable-components hl7v3models_edition2011,snomedctvocab_20110731,loinc_242
The unattended installer does not return output. On succesful completion
of the installation, the
file /tmp/install-mgridhdl.log is
created. When there are errors, the error message will be echoed to the
screen. In the presence of errors, the log messages can be found in the
newest
/tmp/bitrock_installer*.log file.
Installing the module in a database¶
The HDL module must be installed in a database before it can be used. For PostgreSQL 9.3 versions and above, installation with CREATE EXTENSION is available.
For Greenplum Databases, installation consists of running a dedicated script on the Greenplum cluster.
Installing on PostgreSQL¶
Installation in a PostgreSQL servers 9.3 or higher can be done by creating extensions. The extensions check their requirements, which prevents common mistakes such as loading a RIM without the necessary vocabulary. With extensions it is also easy to keep track which modules are loaded, as is shown in How do I view which healthcare modules and vocabularies are loaded?.
Create a RIM 2011 database on PostgreSQL (≥ 9.3)¶
createuser --superuser hcuser
createdb -U hcuser hcdb
psql -U hcuser hcdb
ALTER DATABASE hcdb SET search_path=public,hdl,hl7,r1,"$user";
CREATE EXTENSION hl7basetable;
CREATE EXTENSION ucum;
CREATE EXTENSION hl7;
CREATE EXTENSION hl7v3vocab_edition2011;
CREATE EXTENSION hl7v3datatypes;
CREATE EXTENSION hl7v3rim_edition2011;
CREATE EXTENSION hl7v3crud_edition2011;
CREATE EXTENSION hl7v3_c_contextconduction_edition2011;
ALTER ROLE hcuser WITH NOSUPERUSER;
hl7basetable- this extension creates catalog support tables used by the hl7 and ucum extensions, and must be loaded before all the other extensions.ucum- this extension creates the tables and conversion support functions for UCUM, the Unified Codes for Units of Measure. This extension is a prerequisite for thehl7extensionsPQdatatype.hl7- this extension contains the base types, functions and operators.hl7v3vocab_edition2011- vocabulary extensions populate the catalog support relations for theCVdatatype with the HL7v3 codesystems. MGRID includes vocabulary extensions for all HL7v3 Normative Editions. It must be loaded before the datatype extensions as well as before any database that creates table columns with a conceptdomain, e.g. a RIM database with matching Normative Edition.hl7v3datatypes- this extension loads the HDL datatypes.
At this point no tables are created yet; the database has datatypes and vocabulary support only. This can be used as starting point for a custom database that uses the datatypes, such as a clinical research datawarehouse schema. Another possibility is to proceed creating a full RIM database, by loading the following extensions:
hl7v3rim_edition2011- this extension creates tables that match the RIM of Normative Edition 2011. The rim script version should match the vocabulary version, loading e.g a RIM from 2011 on a vocabulary script from 2005 will give errors due to unknown conceptdomains. Thesearch_pathshould includer1orr2to select the complex types version used in the selected RIM version.hl7v3crud_edition2011- this extension creates basic insert functions for the RIM classes, and is used by the parsers generated by the MGRID Messaging Toolkit and other additional software available from MGRID.hl7v3_c_contextconduction_edition2011- this script creates triggers that implement conduction indicator based (c) context conduction. This is one of several alternative implementations of context conduction, which are described in section Context conduction.
Installing on Greenplum¶
Installation of the HDL module in a database
on Greenplum can be done with the
script install_hdl.sh, installed in
the sharedir/contrib directory
of the Greenplum installation.
The script will perform these actions on a selected database on a Greenplum cluster:
- Copy the shared object files of the HDL module to all the
non-master segment hosts in the Greenplum cluster.
The
install_hdl.shscript queries the Greenplum catalog tablegp_segment_configurationto determine the host list. The script usesgpscpto copy the shared object files. - Create the database schemas
hdlandhl7to contain the HDL types. Create support functions ported from PostgreSQL to Greenplum that are needed by the HDL. - Create the support tables of the
pqandcvsimple types. These types require additional data to function and this step creates these tables. - Create UCUM and uuid functions. Load UCUM data.
- Create all the HDL types and functions. This step uses the
original
hl7--2.0.sqlfor PostgreSQL as input, and rewrites the SQL for Greenplum on the fly. Conversions made include removing typmod in/out, removing MERGES for operators, removing COST for functions and removing GIN operator clases. Loading of the HDL types and functions in Greenplum can take up to a minute.
The install_hdl.sh script takes the following arguments als parameters:
- The database name of the database where the
HDL module must be created. If this parameter is not supplied,
the script will default to the
PGDATABASEenvironment variable if not null, andpostgresotherwise. - The port number where the Greenplum master
segment is running on. If this parameter is not supplied, the
script will default to the
PGPORTenvironment variable. - The host name of the Greenplum master
segment. If this parameter is not supplied, the script will
default to
127.0.0.1. - The database user name of the database
administrator user with superuser rights. If this parameter is
not supplied, the script will default
to the
PGUSERenvironment variable.
Loading the HDL module in a database on Greenplum¶
psql --version
psql (PostgreSQL) 8.2.15
contains support for command-line editing
createdb hcdb
$(pg_config --sharedir)/contrib/install_hdl.sh hcdb 15432 localhost
Performing master step 01 schemas ... done
Performing segment step 02 basetables ... done
Performing master step 03 ucum-and-uuid-funcs ... done
Performing segment step 04 ucum-data ... done
Performing master step 05 hdl ... done
## THE SEARCH_PATH IS NECESSARY TO BE ABLE TO USE THE HEALTHCARE DATATYPES ##
psql hcdb -c "ALTER DATABASE hcdb SET search_path TO public,hl7,hdl,r1"
psql hcdb -tc "SELECT '10 [ft_us]'::pq + '1 [yd_us]'"
13 [ft_us]
At this point there are no RIM tables created yet. You can check
correct load of the HDL module in the database by performing a physical
quantity computation, as is done in the example above. If the HDL was
not loaded correctly, check
the /tmp/mgrid*log files that
correspond with the
/tmp/mgrid*sql files, for error
messages.
To load a RIM normative edition, it is necessary to adapt the DDL from
the hl7v3rim_edition* sql files. This adaptation
will take DDL for PostgreSQL, remove PostgreSQL specific features, such
as typmods and GIN operator classes, and
add Greenplum specific features, such as
distribution keys, columnar storage settings and partitioning.
Create a RIM database on Greenplum¶
The next example shows the minimum transformation needed to
transform a PostgreSQL RIM SQL file to Greenplum. PostgreSQL-only
constructs are removed. Simple type cv is transformed
to CS, type modifiers are removed. Specific instructions
for Greenplum are added to set distribution keys and storage
parameters. Of interest is the removal of inheritance for
the Observation table, since inheritance is not
supported for tables that will be partitioned or stored columnar. Note
that the changes below are supplied as example; actual storage and
partitioning parameters must be configured depending on the data stored
and queries run.
psql --version
psql (PostgreSQL)
8.2.15 contains support for command-line editing
## Note: HDL must be loaded and the search_path altered, as is done in the
## previous example!
cat $(pg_config --sharedir)/contrib/hl7v3rim_edition2011--2.0.sql | \
sed -e 's/MODULE_PATHNAME/\$libdir\/hl7/g' \
-e 's/, TYPMOD_.*$//g' \
-e 's/, MERGES//g' \
-e 's/^COST[ 0-9]\+$//g' \
-e '/CREATE OPERATOR CLASS "*gin_/,/;$/d' \
-e '/DELETE FROM pg_depend/,/;$/d' \
-e '/ALTER TABLE/d' \
-e '/SELECT __warn_extension_deps_removal/,/;$/d' \
-e 's/\([^a-z]\)cv\(([^)]\+)\)/\1"CS"\2/gi' \
-e 's/\([^a-z]CS"*\)([^)]\+)/\1/gi' \
-e 's/\([^a-z]set"*\)([^)]\+)/\1/gi' \
-e 's/PRIMARY KEY,/PRIMARY KEY, _id_cluster BIGINT,/g' \
-e 's/_clonename TEXT,/_clonename TEXT, _pond_timestamp TIMESTAMPTZ, _lake_timestamp TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP, _record_hash TEXT, _record_weight INT,/g' \
-e 's/"source" BIGINT, "target" BIGINT,/"source" BIGINT, "target" BIGINT, "source_original" BIGINT, "target_original" BIGINT,/g' \
-e 's/"act" BIGINT, "role" BIGINT,/"act" BIGINT, "role" BIGINT, "act_original" BIGINT, "role_original" BIGINT,/g' \
-e 's/"player" BIGINT, "scoper" BIGINT,/"player" BIGINT, "scoper" BIGINT, "player_original" BIGINT, "scoper_original" BIGINT,/g' \
-e '/CREATE TABLE "[[:alpha:]]*Participation"/ {s/_clonename TEXT,/_clonename TEXT, _origin BIGINT,/}' \
-e 's/ PRIMARY KEY//g' \
-e 's/ REFERENCES \"[[:alpha:]]*\"//g' \
-e 's/"code" "CD",/_code_code TEXT, _code_codesystem TEXT, "code" "CD",/g' \
-e 's/"value" "ANY",/_value_pq pq,_value_pq_value NUMERIC, _value_pq_unit TEXT,_value_code_code TEXT, _value_code_codesystem TEXT, _value_int INT, _value_real NUMERIC, _value_ivl_real ivl_real, "value" "ANY",/g' \
-e 's/, "effectiveTime"/, _effective_time_low TIMESTAMPTZ, _effective_time_low_year INT, _effective_time_low_month INT, _effective_time_low_day INT, _effective_time_high TIMESTAMPTZ, _effective_time_high_year INT, _effective_time_high_month INT, _effective_time_high_day INT, "effectiveTime"/g' \
-e '/CREATE TABLE "Act"/ {s/;//}' \
-e '/CREATE TABLE "Act"/ {a\
WITH (appendonly = false)\
DISTRIBUTED BY (_id);
}' \
-e '/CREATE TABLE "Participation"/ {s/;//}' \
-e '/CREATE TABLE "Participation"/ {a\
WITH (appendonly = true, compresslevel = 6)\
DISTRIBUTED BY (act);\
ALTER TABLE "Participation" SET DISTRIBUTED BY (act);
}' \
-e '/CREATE TABLE "[[:alpha:]]*"/ {s/ INHERITS (\"Observation\")//}' \
-e '/CREATE TABLE "Observation"/ {s/ INHERITS (\"[[:alpha:]]*\");//}' \
-e '/CREATE TABLE "Observation"/ {a\
WITH (appendonly = true, orientation = column, compresslevel = 6)\
DISTRIBUTED BY (_id)\
PARTITION BY RANGE (_effective_time_low_year)\
SUBPARTITION BY RANGE (_effective_time_low_month)\
SUBPARTITION TEMPLATE (\
START (1) END (13) EVERY (1),\
DEFAULT SUBPARTITION other_months )\
(START (2008) END (2016) EVERY (1),\
DEFAULT PARTITION other_years );
}'| PGOPTIONS='--client-min-messages=warning' psql -q1 --dbname hcdb
Connect with psql to the Greenplum database to verify that tables have been created.
psql hcdb
psql (8.2.15)
Type "help" for help.
hcdb=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+------------------------------------+----------+-------+----------------------
hdl | pg_cbinding | table | m | heap
hdl | pg_code | table | m | heap
hdl | pg_conceptdomain | table | m | heap
hdl | pg_oid | table | m | heap
hdl | pg_oid_seq | sequence | m | heap
hdl | pg_oidversion | table | m | heap
hdl | pg_ucumprefix | table | m | heap
hdl | pg_ucumunit | table | m | heap
public | Access | table | m | heap
public | Account | table | m | heap
public | Acknowledgement | table | m | heap
public | AcknowledgementDetail | table | m | heap
public | Act | table | m | heap
public | ActRelationship | table | m | heap
..
public | QuerySpec | table | m | heap
public | Role | table | m | heap
public | RoleLink | table | m | heap
public | SortControl | table | m | heap
public | SubstanceAdministration | table | m | heap
public | Supply | table | m | heap
public | Transmission | table | m | heap
public | TransmissionRelationship | table | m | heap
public | Transmission_CommunicationFunction | table | m | heap
public | WorkingList | table | m | heap
(70 rows)
hcdb=# \d "Observation"
Append-Only Columnar Table "public.Observation"
Column | Type | Modifiers
---------------------+-----------+-----------
_id | bigint |
_mif | text |
_clonename | text |
nullFlavor | "CS" |
realmCode | set |
typeId | "II" |
templateId | "LIST_II" |
classCode | "CS" |
moodCode | "CS" |
id | "SET_II" |
code | "CD" |
actionNegationInd | bl |
negationInd | bl |
derivationExpr | st |
title | "ED" |
text | "ED" |
statusCode | "CS" |
effectiveTime | "GTS" |
activityTime | "GTS" |
availabilityTime | ts |
priorityCode | set |
confidentialityCode | set |
repeatNumber | ivl_int |
interruptibleInd | bl |
levelCode | "CS" |
independentInd | bl |
uncertaintyCode | "CS" |
reasonCode | set |
languageCode | "CS" |
isCriterionInd | bl |
value | "ANY" |
valueNegationInd | bl |
interpretationCode | set |
methodCode | set |
targetSiteCode | "SET_CD" |
Checksum: f
Distributed by: (_id)
hcdb=# explain select * from "Observation";
QUERY PLAN
---------------------------------------------------------------------------------------
Gather Motion 2:1 (slice1; segments: 2) (cost=0.00..0.00 rows=1 width=1096)
-> Append-only Columnar Scan on "Observation" (cost=0.00..0.00 rows=1 width=1096)
(2 rows)